


CS336 Lecture Notes 1
本文为本人学习相关开源课程过程中,整理的个人学习笔记及作业解答,核心目的仅用于记录个人学习轨迹、巩固所学知识、梳理学习思路,全程为个人自主学习使用,不具备任何商业用途,也不构成任何形式的课程辅导或标准答案参考。
需特别说明的是,由于本人学习进度及知识储备有限,笔记内容及作业解答中可能存在大量纰漏、思路偏差甚至错误,仅代表本人当时的学习理解,不具备权威性和准确性。
在此郑重提醒:请勿将本文中的任何作业解答复制粘贴,作为自身所修课程的提交答案。任何因抄袭本文内容导致的课程成绩问题、学术诚信问题,均由抄袭者自行承担全部责任,本人不承担任何相关连带责任。
同时,本文所分享的内容均基于开源课程的公开内容整理,尊重原课程创作者的知识产权,若涉及相关内容的版权问题,请及时联系本人,本人将第一时间进行调整或删除。
感谢各位读者的理解与支持,也欢迎大家针对笔记及解答中的问题提出宝贵建议,共同交流学习、共同进步。
- 课程网站: https://cs336.stanford.edu/
- Lec01 资料: lecture_01.py
- Lec02 资料: lecture_02.py
Tokenization
简单来说就是将输入(一般为文本)编码为一个 token 序列,可以在 Tiktokenizer 感受这一过程。

Resource Accounting (Systems)
Lec02 核心问题:给定固定资源(计算、内存),如何训练最好的模型?即最大化计算效率。
动机问题
这里提出了两个经典的”餐巾纸计算”问题:
- 训练时间估算:在 1024 张 H100 上训练 70B 参数模型处理 15T tokens 需多久?
total_flops = 6 × 70e9 × 15e12h100_flop_per_sec = 1979e12 / 2 # 无稀疏化mfu = 0.5flops_per_day = h100_flop_per_sec * mfu * 1024 * 60 * 60 * 24days = total_flops / flops_per_daytotal_flops计算公式中的6来源于前向传播中每个参数参与 1 次乘 + 1 次加,反向传播中计算梯度需要 2 次矩阵乘。详细推导见 How To Scale Your Model。- NVIDIA 官方 datasheet 标注:H100 的 BF16/FP16 Tensor Core 峰值算力为 1,979 TFLOPS, 但是这个数值的前提是**启用了结构化稀疏(2:4 sparsity)加速。
- 最大模型估算:8 张 H100 用 AdamW 能训练多大的模型?
h100_bytes = 80e9bytes_per_parameter = 2 + 2 + (4 + 4) # parameters (2), gradients (2), optimizer state (4 + 4)num_parameters = (h100_bytes * 8) / bytes_per_parameter内存计算
Tensor 基础
Tensor 是存储一切的基础:数据、参数、梯度、优化器状态、激活值。
每一个 Tensor 都有自己的维度,用 Rank 表示维度数。
在 Transformer 中经常见到四维的 tensor:(B, S, H, D) 即 batch、序列长度、head 数、每 head 维度。
B = 32 # Batch sizeS = 16 # Sequence lengthH = 16 # Number of headsD = 64 # Hidden dimension per headx = torch.zeros(B, S, H, D)数据类型
- fp32:默认类型,4 bytes/值,精度高但内存大
- fp16:2 bytes/值,但动态范围差(小数会 underflow)
- bf16:Google Brain 开发,2 bytes 但保持 fp32 动态范围,分辨率略差
- fp8:2022 年标准化,H100 支持 E4M3 和 E5M2 两种变体
- fp4 (NVFP4):仅 4 bits,配合 block-wise scale factor
混合精度训练 Mixed Precision Training
不同的精度对训练的影响:
- 采用 fp32 训练可行,但是需要占用大量内存
- 采用 fp16 甚至 bf16 训练都存在风险,可能会出现训练不稳定的问题
解决方案:[Micikevicius et al. 2018]
- 用 bf16 存参数、激活值、梯度(节省内存)
- 用 fp32 存优化器状态(稳定性)
PyTorch 有自动处理类型转换 AMP 库。[docs]
计算量计算
FLOPs 定义
- FLOPs:浮点运算次数(计算量)
- FLOP/s:每秒浮点运算数(硬件速度)
H100 峰值约 1979 teraFLOP/s(稀疏),非稀疏约一半。
MFU(Model FLOPs Utilization)
MFU = 实际 FLOP/s / 理论峰值 FLOP/s。MFU ≥ 0.5 已是优秀水平。
算术强度
如何计算一样东西:
- 将输入从内存发送到加速器
- 在加速器中进行计算
- 将输出从加速器中发送到内存
所需时间取决于:
- 加速器的计算速度 (FLOP/s)
- 内存带宽 (bytes/s)
assert h100_flop_per_sec == 1979e12 / 2 # Half without sparsityassert h100_bytes_per_sec == 3.35e12假设某一个计算过程需要传输 bytes_ 字节的数据,总共的浮点计算量是 flops ,那么
communication_time = bytes_ / h100_bytes_per_seccomputation_time = flops / h100_flop_per_sec假设计算和通信可以完美的覆盖,那么
total_time = max(communication_time, computation_time)瓶颈分析:
- 内存受限(Memory-bound):communication time > computation time(数据传输是瓶颈)
- 计算受限(Compute-bound):communication time < computation time(计算是瓶颈)
另一种视角:
加速器强度(Accelerator intensity):加速器每传输一字节可完成多少计算量?
h100_accelerator_intensity = h100_flop_per_sec / h100_bytes_per_sec # 295.37算术强度(Arithmetic intensity):该工作负载每字节可完成多少实际运算量?
arithmetic_intensity = flops / bytes_什么是瓶颈?
内存受限(Memory-bound): arithmetic intensity < accelerator intensity(数据传输是瓶颈)计算受限(Compute-bound): arithmetic intensity > accelerator intensity(计算是瓶颈)
示例:
ReLU
n = 1024 * 1024x = torch.ones(n, dtype=torch.bfloat16, device=cuda_if_available())y = torch.relu(x)
bytes_ = (2 * n) + (2 * n) # Read x, write y (bf16 is 2 bytes/float)flops = n # n comparisons
arithmetic_intensity = flops / bytes_ # ~1/4Relu 是内存受限的。
GeLU
n = 1024 * 1024x = torch.ones(n, dtype=torch.bfloat16, device=cuda_if_available())y = F.gelu(x) # GELU(x) = 0.5 x (1 + tanh(sqrt(2/pi) (x + 0.044715 x^3)))
bytes_ = (2 * n) + (2 * n) # Read x, write y (bf16 is 2bytes/float)flops = 20 * n # tanh can be approximated in various ways (e.g., polynomials)
arithmetic_intensity = flops / bytes_ # ~5算术强度更高但仍内存受限(故 ReLU 并不比 GeLU 快)
点积
n = 1024 * 1024x = torch.ones(n, dtype=torch.bfloat16, device=cuda_if_available())w = torch.ones(n, dtype=torch.bfloat16, device=cuda_if_available())y = x @ w
bytes_ = (2 * n) + (2 * n) + 2 # Read x, read w, write yflops = 2 * n - 1 # n multiplications, n - 1 additions
arithmetic_intensity = flops / bytes_ # ~1/2内存受限!
矩阵向量乘
n = 1024x = torch.ones(n, dtype=torch.bfloat16, device=cuda_if_available())w = torch.ones(n, n, dtype=torch.bfloat16, device=cuda_if_available())y = x @ w
bytes_ = (2 * n) + (2 * n * n) + (2 * n) # Read x, read w, write yflops = n * (2 * n - 1) # n dot-products
arithmetic_intensity = flops / bytes_ # ~1内存受限!
矩阵乘法
n = 1024x = torch.ones(n, n, dtype=torch.bfloat16, device=cuda_if_available())w = torch.ones(n, n, dtype=torch.bfloat16, device=cuda_if_available())y = x @ w
bytes_ = (2 * n * n) + (2 * n * n) + (2 * n * n) # Read x, read w, write yflops = n * n * (2 * n - 1) # n^2 dot products
arithmetic_intensity = flops / bytes_ # ~n/3当 n 足够大时是计算受限的!
关键结论
训练 Transformers 涉及大矩阵乘法,故计算受限;推理时矩阵-向量乘法占主导,故内存受限。
Roofline 分析
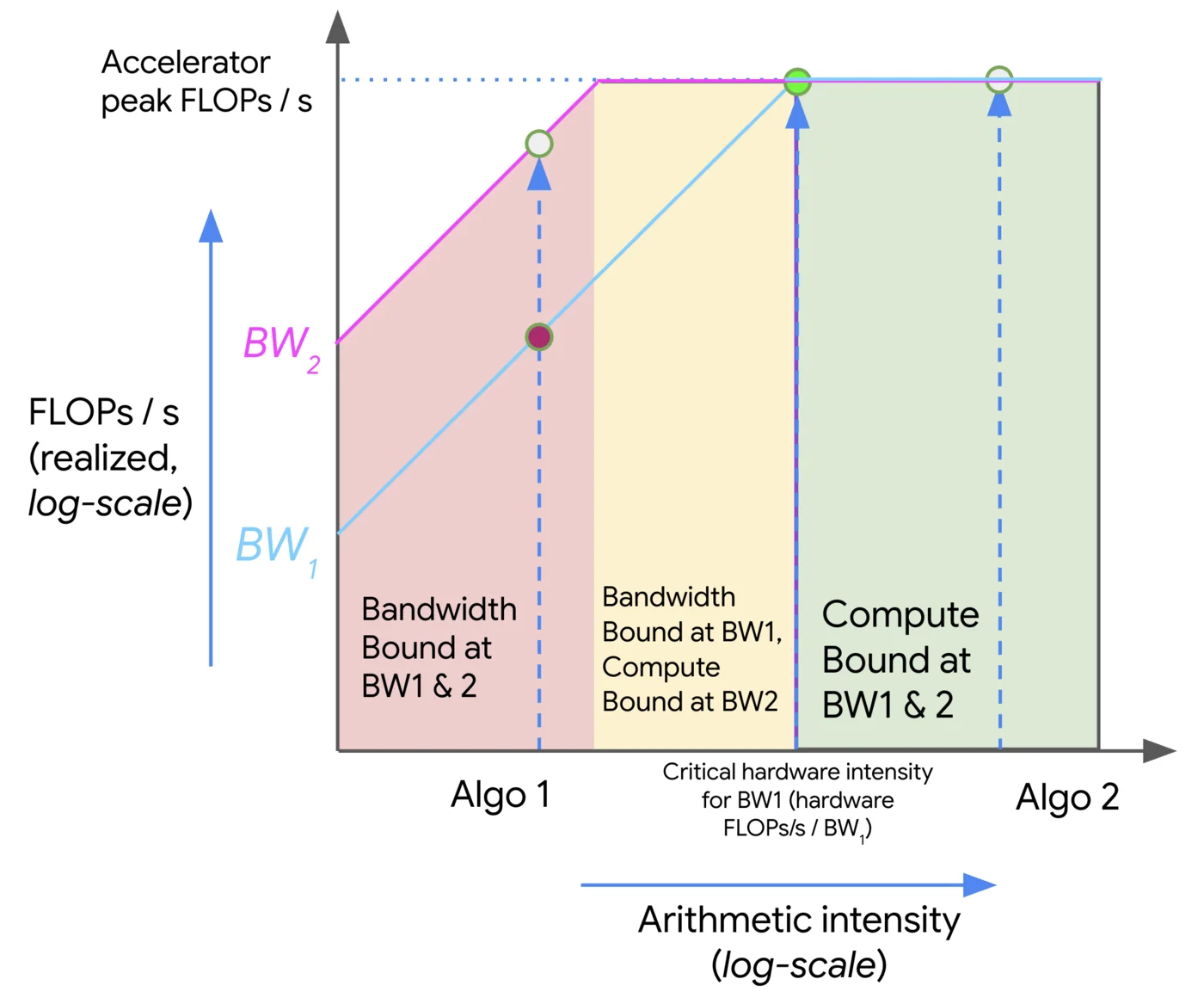
- x 轴上的每一个切片都代表一项特定计算(具有特定的算术强度)
- 每个分段线性函数对应一种特定的硬件
- 拐点为加速器强度(从内存受限向计算受限的过渡阶段)
我们可以将这一点关联回 MFU:
MFU = min(1, arithmetic_intensity / accelerator_intensity)训练资源计算

class Block(nn.Module): """Simple block that applies a linear transformation followed by a ReLU nonlinearity.""" def __init__(self, dim: int): super().__init__() self.weight = nn.Parameter(torch.randn(dim, dim) / math.sqrt(dim))
def forward(self, x: torch.Tensor) -> torch.Tensor: x = x @ self.weight # Linear x = F.relu(x) # Activation return x
class DeepNetwork(nn.Module): """Map `dim`-vector to a `dim`-vector.""" def __init__(self, dim: int, num_layers: int): super().__init__() self.layers = nn.ModuleList([Block(dim) for i in range(num_layers)])
def forward(self, x: torch.Tensor) -> torch.Tensor: # Apply all the layers sequentially for layer in self.layers: x = layer(x) return x
# Define the networkB = 2D = 4 # Dimensionality of input, activations, and outputL = 3 # Number of layersmodel = DeepNetwork(dim=D, num_layers=L).to(cuda_if_available())使用 AdaGrad 优化器
- Momentum = SGD + 梯度的指数移动平均
- AdaGrad = SGD + 梯度平方的累计平均
- RMSProp = AdaGrad,但对梯度平方采用指数移动平均
- Adam = RMSProp + Momentum
AdaGrad [Duchi et al. 2011]
optimizer = AdaGrad(model.parameters(), lr=0.01)state = model.state_dict()
# Compute gradientsx = torch.randn(B, D, device=cuda_if_available())y = torch.tensor([4., 5.], device=cuda_if_available())pred_y = model(x).mean()loss = F.mse_loss(input=pred_y, target=y)loss.backward()
# Take a stepoptimizer.step()optimizer_state = {i: dict(p_state) for i, (p, p_state) in enumerate(optimizer.state.items())}
# Free up the memoryoptimizer.zero_grad(set_to_none=True)内存组成
total_memory = parameter_memory + activation_memory + gradient_memory + optimizer_state_memory以 bf16 训练、AdamW 优化器为例:
parameter_memory = 2 * num_parameters # (2 bytes for bf16)gradient_memory = 2 * num_parameters # (2 bytes for bf16)optimizer_state_memory = (4 + 4) * num_parameters # (4 bytes for fp32)activation_memory = 2 * (B * D * L) # (2 bytes for bf16)内存优化技术
梯度累积
大 batch size 提升训练稳定性,但 activation memory 随 batch size 增长,盲目地增加 batch size 很有可能导致 OOM。
B = 64 # Batch sizeD = 1024 # DimensionalityL = 16 # Number of layersactivation_memory = 2 * B * D * L # (2 bytes for bf16)解决方案:
- 在 micro-batch 上计算梯度
- 累加梯度(不清零梯度)
- 每经过
batch_size / micro_batch_size步,更新参数并将梯度清零
micro_batch_size = 256activation_memory = 2 * micro_batch_size * D * L # (2 bytes for bf16)激活检查点(Activation Checkpointing)
对于训练,我们需要将所有层的激活值存下来; 但是对于推理,我们不需要进行梯度计算,所以我们只需要存当前层的激活值。
如何减少激活值所占用的内存呢?
解决方法 gradient checkpointing 也叫做 rematerialization,核心 idea:
- Forward:只保留部分层激活值
- Backward:从检查点重新计算缺失激活值
Philosophy:牺牲计算换取内存。
# 存储所有激活值: x g1 h1 g2 h2 g3 h3 g4 h4# 激活检查点策略: x h1 h2 h3 h4能否进一步压缩内存?尤其是对于极深的网络(L 很大时)?
# 存储每一层: | h1 h2 h3 h4 h5 h6 h7 h8 h9 |# 完全不存储: | |# 选择性存储: | h3 h6 h9 |检查点应该设置多频繁?
- 若保存每一层的激活值:激活内存为
O(L),反向传播无需重新计算。 - 若完全不保存激活值:激活内存为
O(1),但计算量飙升至O(L^2)(每一层反向传播都需从网络头部重新前向计算)。 - 若每隔
sqrt(L)层保存一次:激活内存降至O(sqrt(L)),重新计算量保持在O(L)。
总结要点
- 一切都是 tensor 操作(参数、梯度、激活值、优化器状态、数据)
- 每训练步 (step/batch) FLOPs ≈ 6 × 数据点数 × 参数数量 (数据点数指的是 token 数)
- 算术强度决定瓶颈:矩阵乘法计算受限,逐元素操作内存受限
- 梯度累积、激活检查点:用额外计算换取更大 batch size
支持与分享
如果这篇文章对你有帮助,欢迎分享给更多人或赞助支持!